神经网络优化学习思考
本文共 1260 字,大约阅读时间需要 4 分钟。
神经网络优化学习思考
本文记录学习过程的一些思考,整体前后逻辑性不是很连贯。神经网络的主要工作可以总结为优化,而整个优化过程大致如下流程(手懒,直接上照骗了):

超参数
网络的层数,权重个数,偏置个数以及初始化值,卷积核的大小和层数,学习率等等。
为什么分三个集合
评估模型的重点是将数据划分为三个集合:训练集、验证集和测试集。在训练数据上训练
模型,在验证数据上评估模型。一旦找到了最佳参数,就在测试数据上最后测试一次。 你可能会问,为什么不是两个集合:一个训练集和一个测试集?在训练集上训练模型,然 后在测试集上评估模型。这样简单得多! 原因在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超 参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验 证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良 好的模型配置。因此,如果基于模型在验证集上的性能来调节模型配置,会很快导致模型在验 证集上过拟合,即使你并没有在验证集上直接训练模型也会如此。【1】可用数据少的话怎么训练数据
从训练方法上 针对此情况 有三种经典的评估方法:简单的留出验证、K 折验证,以及带有打乱数据的重复K 折验证。
留出验证
留出一定比例的数据作为测试集。在剩余的数据上训练模型,然后在测试集上评估模型。
如前所述,为了防止信息泄露,你不能基于测试集来调节模型,所以还应该保留一个验证集。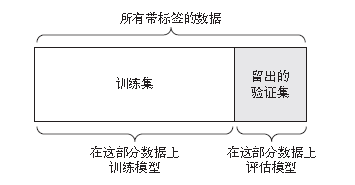
K折验证
将数据划分为大小相同的K 个分区。对于每个分区i,在剩余的K-1 个分区上训练模型,然后在分区i 上评估模型。最终分数等于K 个分数的平均值。对于不同的训练集- 测试集划分,如果模型性能的变化很大,那么这种方法很有用。与留出验证一样,这种方法也需要独立的验证集进行模型校正。

带有打乱数据的重复K 折验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数
据的重复K 折验证(iterated K-fold validation with shuffling)。具体做法是多次使用K 折验证,在每次将数据划分为K 个分区之前都先将数据打乱。最终分数是每次K 折验证分数的平均值。注意,这种方法一共要训练和评估P×K 个模型(P是重复次数),计算代价很大。【1】数据增强
另外从数据本身还可以利用 数据增强技术 来 扩大数据集的规模。数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信训练集的随机变换来增加(augment)样本。其目标是,模型在训练时不会两次查看完全相同的训练样本。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。 然而 数据增强往往 针对于图像的方法比较多,针对于时间序列,如语音的数据增强方法就比较少了 。待实践和学习过后再总结这方面的经验。
参考资料
【1】Deep Learning With Python 中文版 弗朗索瓦.肖莱 著。张亮 译。
转载地址:http://juyrf.baihongyu.com/
你可能感兴趣的文章
Java 8新的时间日期库
查看>>
Chrome开发者工具
查看>>
Java工程师成神之路
查看>>
如何在 Linux 上自动设置 JAVA_HOME 环境变量
查看>>
MSSQL复习笔记
查看>>
Spring基础知识汇总
查看>>
Chrome扩展插件
查看>>
log4j.xml 日志文件配置
查看>>
如何删除MySql服务
查看>>
BAT Java和Rti环境变量设置
查看>>
NodeJs npm install 国内镜像
查看>>
python3.5.2 mysql Exccel
查看>>
mysqlDump 导出多表,其中部分表有限制数据内容
查看>>
vi 替换方法
查看>>
BAT 相关
查看>>
ANT集成SVNANT访问SVN(Subversion)
查看>>
高可用架构-- MySQL主从复制的配置
查看>>
jvm调优-从eclipse开始
查看>>
构建微服务:Spring boot 入门篇
查看>>
jvm调优-命令大全(jps jstat jmap jhat jstack jinfo)
查看>>